Sensitivity-Aware Mixed-Precision Quantization for ReRAM-based Computing-in-Memory
By Guan-Cheng Chen 1, Chieh-Lin Tsai 2, Pei-Hsuan Tsai 1, Yuan-Hao Chang 2
1 National Cheng Kung University, Tainan, Taiwan
2 National Taiwan University, Taipei, Taiwan
Abstract
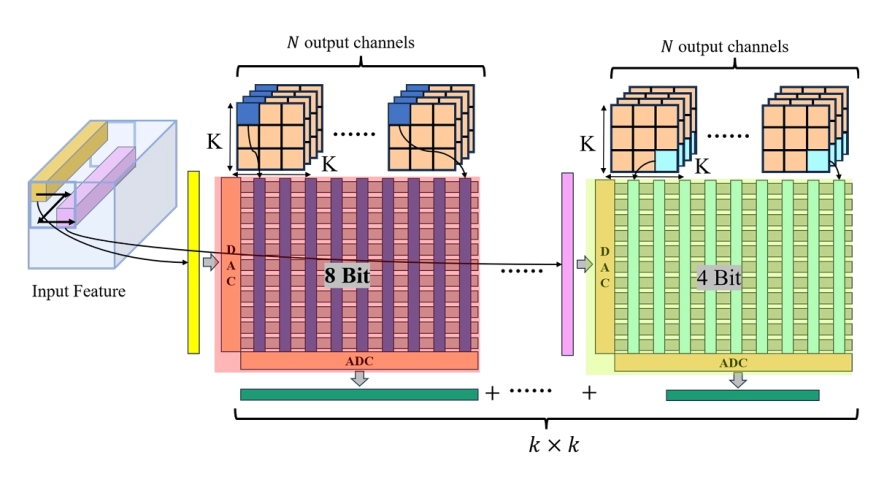
Compute-In-Memory (CIM) systems, particularly those utilizing ReRAM and memristive technologies, offer a promising path toward energy-efficient neural network computation. However, conventional quantization and compression techniques often fail to fully optimize performance and efficiency in these architectures. In this work, we present a structured quantization method that combines sensitivity analysis with mixed-precision strategies to enhance weight storage and computational performance on ReRAM-based CIM systems. Our approach improves ReRAM Crossbar utilization, significantly reducing power consumption, latency, and computational load, while maintaining high accuracy. Experimental results show 86.33% accuracy at 70% compression, alongside a 40% reduction in power consumption, demonstrating the method's effectiveness for power-constrained applications.
To read the full article, click here
Related Semiconductor IP
- Adaptive Voltage Scaling (AVS) Bus Target IP
- Adaptive Voltage Scaling (AVS) Bus Host Controller
- NoC Interconnect IP Generator
- Over-Voltage Lockout (OVLO) IP
- Verification IP for Universal Chiplet Interconnect Express (UCIe) up to 3.0
Related Articles
- VitaLLM: A Versatile and Tiny Accelerator for Mixed-Precision LLM Inference on Edge Devices
- Pyramid Vector Quantization and Bit Level Sparsity in Weights for Efficient Neural Networks Inference
- ACE: Confidential Computing for Embedded RISC-V Systems
- One Platform, Five Libraries: Certus Semiconductor’s I/O IP Portfolio for Every Application on TSMC 22nm ULL/ULP Technologies
Latest Articles
- Low-Energy Reduced RISC-V Instruction Subset Processor for Tsetlin Machine Inference at the Edge
- Si-GT: Fast Interconnect Signal Integrity Analysis For Integrated Circuit Design Via Graph Transformers
- Hardware Mechanisms to Dynamically Throttle AI Performance
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers