OpenEye: A Scalable Open-Source Hardware Accelerator for DNNs
By Denis Lebold 1 and Hendrik Wöhrle 1,2
1 University of Duisburg-Essen, Germany
2 Fraunhofer Institute for Microelectronic Circuits and Systems, Germany
Abstract
The increasing computational complexity of deep neural network inference poses significant challenges for efficient hardware acceleration on embedded platforms, particularly with respect to resource consumption and scalability. This work presents OpenEye, a scalable and sparsity-aware FPGA-based hardware accelerator designed to efficiently execute common neural network operations such as convolutions, dense layers, and pooling.
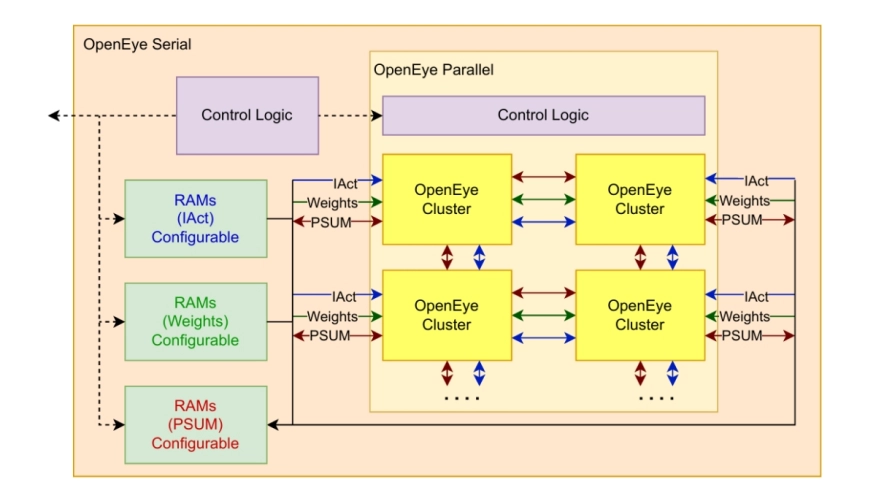
OpenEye is based on a highly parameterizable architecture composed of clusters of processing elements interconnected by a streaming-based dataflow. The paper provides a detailed explanation of the internal operation of the accelerator, including data movement, buffering strategies, control logic, and the coordination between clusters and PEs. The architecture natively supports sparse weights and activations, enabling the efficient processing of sparse data without unnecessary computations or memory accesses.
A key design property of OpenEye is its scalability: the number of clusters and processing elements can be varied to adapt the accelerator to different performance and resource constraints. The design achieves a near-linear scaling of routing and interconnect overhead with increasing PE counts, which is essential for maintaining efficiency on large FPGA devices.
To evaluate scalability across different design points, multiple OpenEye configurations with varying cluster and PE sizes were implemented on a Xilinx ZU19EG FPGA. Representative neural network operations, including convolutional, fully connected, and pooling layers, were used to analyze resource utilization, execution latency, and scalability behavior. The results show favorable trade-offs between performance and resource consumption across the explored configurations.
Keywords: Hardware Accelerator, DNN, Open-Source, Scalability
To read the full article, click here
Related Semiconductor IP
- DSP-Based 112G SerDes
- XTAL oscillator in TSMC-7nm
- GPU
- V-by-One Verification IP
- AI model compression IP
Related Articles
- Heterogeneous SoC Integrating an Open-Source Recurrent SNN Accelerator for Neuromorphic Edge Computing on FPGA
- Open-source hardware for embedded security
- QiMeng: Fully Automated Hardware and Software Design for Processor Chip
- FastPath: A Hybrid Approach for Efficient Hardware Security Verification
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding