CVA6-CFI: A First Glance at RISC-V Control-Flow Integrity Extensions
By Simone Manoni 1, Emanuele Parisi 2, Riccardo Tedeschi 1, Davide Rossi 1,3, Andrea Acquaviva 1, Andrea Bartolini 1
1 Department of Electrical, Electronic, and Information Engineering - University of Bologna, Italy
2 High Performance Domain-Specific Architectures Group - Barcelona Supercomputing Center, Spain
3 Department of Digital Design and Open Hardware - Chips-IT, Italy
Abstract
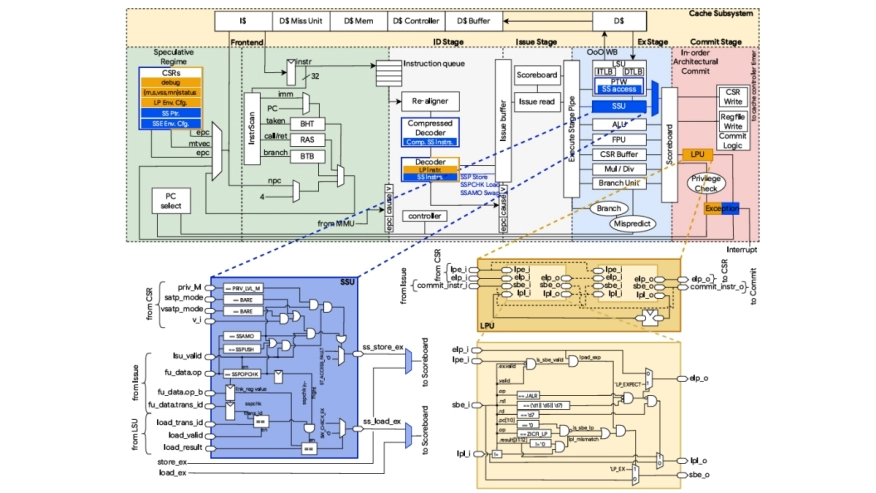
This work presents the first design, integration, and evaluation of the standard RISC-V extensions for Control-Flow Integrity (CFI). The Zicfiss and Zicfilp extensions aim at protecting the execution of a vulnerable program from control-flow hijacking attacks through the implementation of security mechanisms based on shadow stack and landing pad primitives. We introduce two independent and configurable hardware units implementing forward-edge and backward-edge control-flow protection, fully integrated into the open-source CVA6 core. Our design incurs in only 1.0% area overhead when synthesized in 22 nm FDX technology, and up to 15.6% performance overhead based on evaluation with the MiBench automotive benchmark subset. We release the complete implementation as open source.
Index Terms — Control-Flow Integrity, Shadow Stack, Landing Pad, RISC-V
To read the full article, click here
Related Semiconductor IP
- RISC-V Debug & Trace IP
- RISC-V IOPMP IP
- Gen#2 of 64-bit RISC-V core with out-of-order pipeline based complex
- 64-bit RISC-V core with in-order single issue pipeline. Tiny Linux-capable processor for IoT applications.
- Multi-core capable RISC-V processor with vector extensions
Related Articles
- What is JESD204C? A quick glance at the standard
- OpenAccess: first impressions at AMD
- Inside the Xilinx Kintex-7 FPGA: A closer look at the first FPGA to use HKMG technology
- ISA optimizations for hardware and software harmony: Custom instructions and RISC-V extensions
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding