CD-PIM: A High-Bandwidth and Compute-Efficient LPDDR5-Based PIM for Low-Batch LLM Acceleration on Edge-Device
By Ye Lin 1, Chao Fang 1, Xiaoyong Song 2, Qi Wu 1, Anying Jiang 1, Yichuan Bai 1, Li Du 1
1 School of Electronic Science and Engineering, Nanjing University, China
2 China Mobile Research Institute, China
Abstract
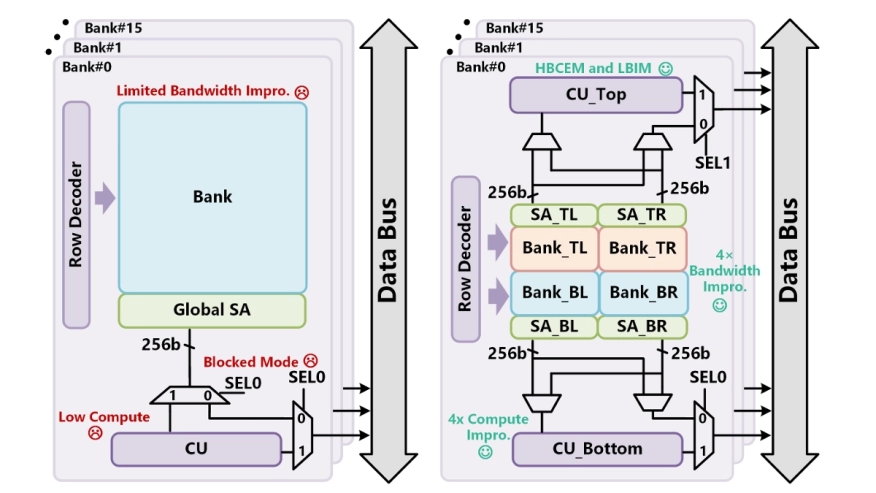
Edge deployment of low-batch large language models (LLMs) faces critical memory bandwidth bottlenecks when executing memory-intensive general matrix-vector multiplications (GEMV) operations. While digital processing-in-memory (PIM) architectures promise to accelerate GEMV operations, existing PIM-equipped edge devices still suffer from three key limitations: limited bandwidth improvement, component under-utilization in mixed workloads, and low compute capacity of computing units (CUs). In this paper, we propose CD-PIM to address these challenges through three key innovations. First, we introduce a high-bandwidth compute-efficient mode (HBCEM) that enhances bandwidth by dividing each bank into four pseudo-banks through segmented global bitlines. Second, we propose a low-batch interleaving mode (LBIM) to improve component utilization by overlapping GEMV operations with GEMM operations. Third, we design a compute-efficient CU that performs enhanced GEMV operations in a pipelined manner by serially feeding weight data into the computing core. Forth, we adopt a column-wise mapping for the key-cache matrix and row-wise mapping for the value-cache matrix, which fully utilizes CU resources. Our evaluation shows that compared to a GPU-only baseline and state-of-the-art PIM designs, our CD-PIM achieves 11.42x and 4.25x speedup on average within a single batch in HBCEM mode, respectively. Moreover, for low-batch sizes, the CD-PIM achieves an average speedup of 1.12x in LBIM compared to HBCEM.
To read the full article, click here
Related Semiconductor IP
- DSP-Based 112G SerDes
- XTAL oscillator in TSMC-7nm
- GPU
- V-by-One Verification IP
- AI model compression IP
Related Articles
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding