A Lightweight High-Throughput Collective-Capable NoC for Large-Scale ML Accelerators
By Luca Colagrande 1, Lorenzo Leone 1, Chen Wu 1, Tim Fischer 1, Raphael Roth 2, Luca Benini 1
1 Integrated Systems Laboratory (IIS), ETH Zurich, Zurich, Switzerland
2 D-ITET, ETH Zurich, Zurich, Switzerland.
Abstract
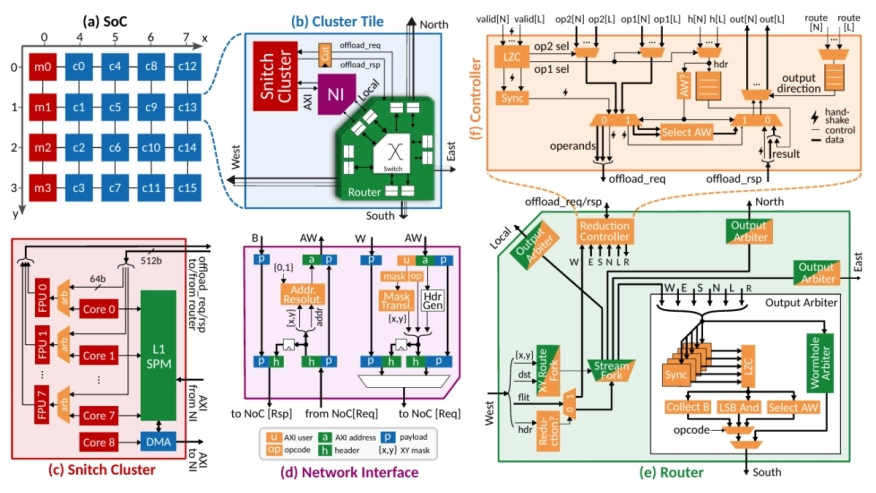
The exponential increase in Machine Learning (ML) model size and complexity has driven unprecedented demand for high-performance acceleration systems. As technology scaling enables the integration of thousands of computing elements onto a single die, the boundary between distributed and on-chip systems has blurred, making efficient on-chip collective communication increasingly critical. In this work, we present a lightweight, collective-capable Network on Chip (NoC) that supports efficient barrier synchronization alongside scalable, high-bandwidth multicast and reduction operations, co-designed for the next generation of ML accelerators. We introduce Direct Compute Access (DCA), a novel paradigm that grants the interconnect fabric direct access to the cores' computational resources, enabling high-throughput in-network reductions with a small 16.5% router area overhead. Through in-network hardware acceleration, we achieve 2.9x and 2.5x geomean speedups on multicast and reduction operations involving between 1 and 32 KiB of data, respectively. Furthermore, by keeping communication off the critical path in GEMM workloads, these features allow our architecture to scale efficiently to large meshes, resulting in up to 3.8x and 2.4x estimated performance gains through multicast and reduction support, respectively, compared to a baseline unicast NoC architecture, and up to 1.17x estimated energy savings.
To read the full article, click here
Related Semiconductor IP
- NoC Interconnect IP Generator
- NoC Silicon IP for RISC-V based chips supporting the TileLink protocol
- NoC Verification IP
- FlexGen Smart Network-on-Chip (NoC) IP
- NoC System IP
Related Articles
- Tackling Network-on-Chip (NoC) Scaling Challenges with a System-technology Co-optimization Approach
- FastPath: A Hybrid Approach for Efficient Hardware Security Verification
- CANDoSA: A Hardware Performance Counter-Based Intrusion Detection System for DoS Attacks on Automotive CAN bus
- Enabling Space-Grade AI/ML with RISC-V: A Fully European Stack for Autonomous Missions
Latest Articles
- Low-Energy Reduced RISC-V Instruction Subset Processor for Tsetlin Machine Inference at the Edge
- Si-GT: Fast Interconnect Signal Integrity Analysis For Integrated Circuit Design Via Graph Transformers
- Hardware Mechanisms to Dynamically Throttle AI Performance
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers