Pipeline Automation Framework for Reusable High-throughput Network Applications on FPGA
By Jean Bruant 1,2, Pierre-Henri Horrein 1, Olivier Muller 2, Frédéric Pétrot 2
1 OVHcloud
2 Univ.Grenoble Alpes, CNRS, Grenoble INP1, TIMA, France
Abstract
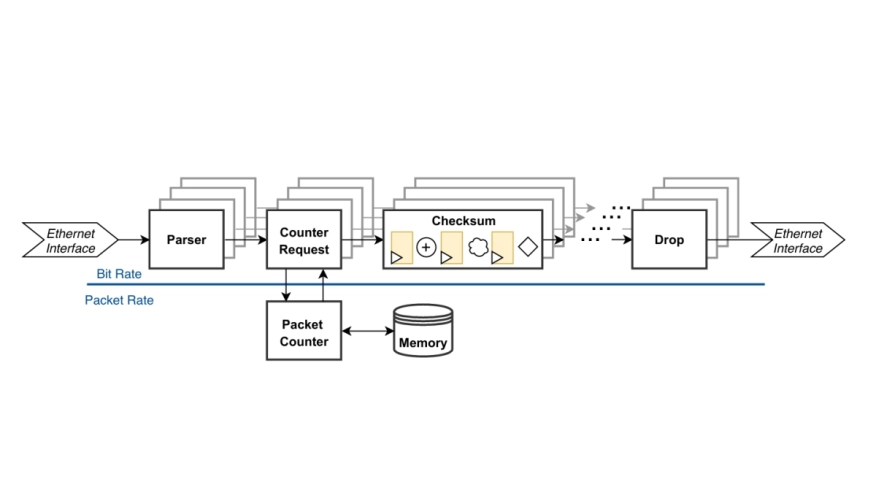
In a context of ever-growing worldwide communication traffic, cloud service providers aim at deploying scalable infrastructures to address heterogeneous needs. Part of the network infrastructure, FPGAs are tailored to guarantee low-latency and high-throughput packet processing. However, slowness of the hardware design process impairs FPGA ability to be part of an agile infrastructure under constant evolution, from incident response to long-term transformation. Deploying and maintaining network functionalities across a wide variety of FPGAs raises the need to fine-tune hardware designs for several FPGA targets. To address this issue, we introduce PAF, an open-source architectural parameterization framework based on a pipeline-oriented design methodology. PAF (Pipeline Automation Framework) implementation is based on Chisel, a Scala-embedded Hardware Construction Language (HCL), that we leverage to interface with circuit elaboration. Applied to industrial network packet classification systems, PAF demonstrates efficient parameterization abilities, enabling to reuse and optimize the same pipelined design on several FPGAs. In addition, PAF focuses the pipeline description on the architectural intent, incidentally reducing the number of lines of code to express complex functionalities. Finally, PAF confirms that automation does not imply any loss of tight control on the architecture by achieving on par performance and resource usage with equivalent exhaustively described implementations.
To read the full article, click here
Related Semiconductor IP
- DSP-Based 112G SerDes
- XTAL oscillator in TSMC-7nm
- GPU
- V-by-One Verification IP
- AI model compression IP
Related Articles
- Survey of Chip Designers on the Value of Formal Verification Across the Spectrum of Applications
- A 24 Processors System on Chip FPGA Design with Network on Chip
- System on Modules (SOM) and its end-to-end verification using Test Automation framework
- FPGA-Accelerated RISC-V ISA Extensions for Efficient Neural Network Inference on Edge Devices
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding