CXL-ClusterSim: Modeling CXL-based Disaggregated Memory Cluster for Pooling and Sharing using gem5 and SST
By Kaustav Goswami, Maryam Babaie, Hoa Nguyen, Venkatesh Akella, and Jason Lowe-Power
University of California, Davis
Abstract
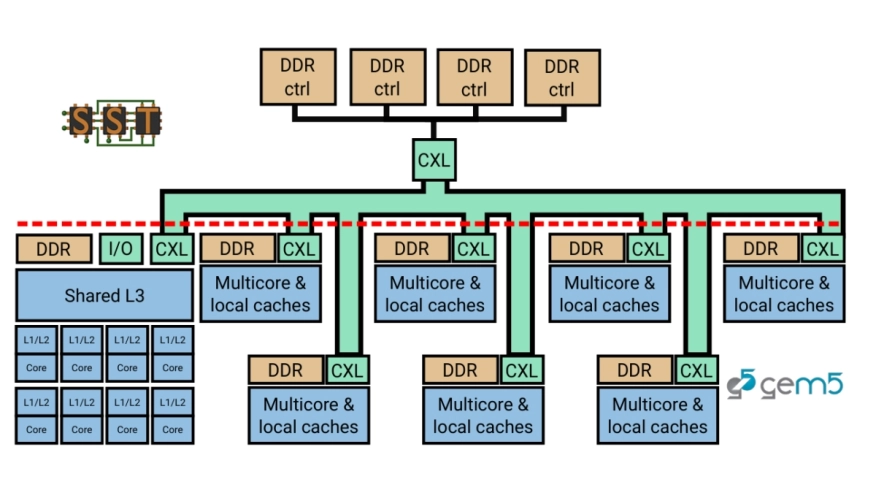
Large-scale AI training and inference require hundreds of gigabytes to terabytes of DRAM with high peak to average utilization ratios, resulting in overprovisioning. In cloud computing, DRAM constitutes a significant share of the cost. Yet, as shown by recent articles, DRAM is heavily under utilized. Memory disaggregation is a solution to both these problems. With the advent of the CXL protocol, there is renewed interest in designing and optimizing computing systems with disaggregated memory. However, at present, there are limited simulation tools available for exploring the design space and evaluating the performance tradeoffs in computer systems with disaggregated memory.
In this paper, we propose CXL-ClusterSim, a full-system modeling and simulation framework by combining the gem5 simulator for fidelity, with the Structural Simulation Toolkit (SST) for parallel simulation. We outline the challenges in creating this simulation infrastructure and present a design that is scalable, flexible, and reasonably fast to help computer architects to explore the design space of CXL-based disaggregated memory and identify new opportunities for hardware/software codesign and performance optimization.
To read the full article, click here
Related Semiconductor IP
- DSP-Based 112G SerDes
- XTAL oscillator in TSMC-7nm
- GPU
- V-by-One Verification IP
- AI model compression IP
Related Articles
- Using scheduled cache modeling to reduce memory latencies in multicore DSP designs
- TeraPool: A Physical Design Aware, 1024 RISC-V Cores Shared-L1-Memory Scaled-up Cluster Design with High Bandwidth Main Memory Link
- Signal Integrity --> LVDS modeling techniques overcome Ibis inaccuracies
- Behavioral Modeling Sets up ATM Design
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding