MING: An Automated CNN-to-Edge MLIR HLS framework
By Jiahong Bi, Lars Schütze and Jeronimo Castrillon
Technische Universitat Dresden, Germany
Abstract
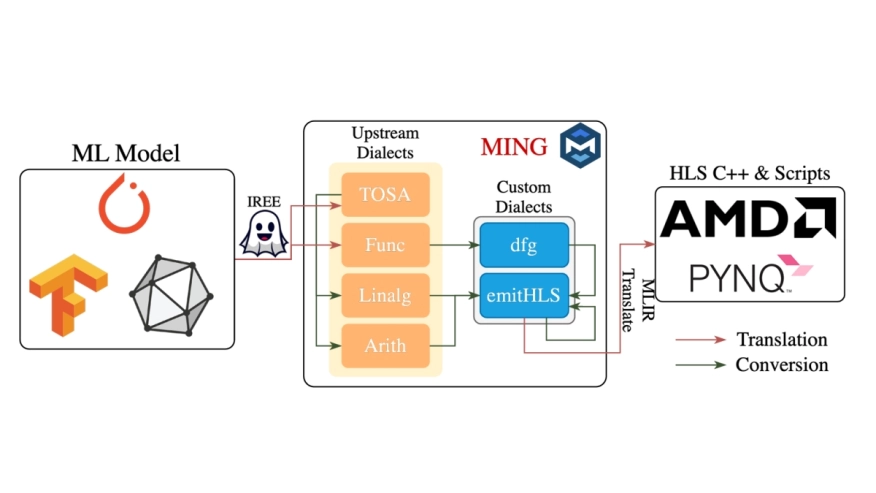
Driven by the increasing demand for low-latency and real-time processing, machine learning applications are steadily migrating toward edge computing platforms, where Field-Programmable Gate Arrays (FPGAs) are widely adopted for their energy efficiency compared to CPUs and GPUs. To generate high-performance and low-power FPGA designs, several frameworks built upon High Level Synthesis (HLS) vendor tools have been proposed, among which MLIR-based frameworks are gaining significant traction due to their extensibility and ease of use. However, existing state-of-the-art frameworks often overlook the stringent resource constraints of edge devices. To address this limitation, we propose MING, an Multi-Level Intermediate Representation (MLIR)-based framework that abstracts and automates the HLS design process. Within this framework, we adopt a streaming architecture with carefully managed buffers, specifically designed to handle resource constraints while ensuring low-latency. In comparison with recent frameworks, our approach achieves on average 15x speedup for standard Convolutional Neural Network (CNN) kernels with up to four layers, and up to 200x for single-layer kernels. For kernels with larger input sizes, MING is capable of generating efficient designs that respect hardware resource constraints, whereas state-of-the-art frameworks struggle to meet.
Index Terms — Hardware Architectures, Compilers, High Level Synthesis, Quantized Neural Network, Edge Computing
To read the full article, click here
Related Semiconductor IP
- Adaptive Voltage Scaling (AVS) Bus Target IP
- Adaptive Voltage Scaling (AVS) Bus Host Controller
- NoC Interconnect IP Generator
- Over-Voltage Lockout (OVLO) IP
- Verification IP for Universal Chiplet Interconnect Express (UCIe) up to 3.0
Related Articles
- DDGEN: An Automated Device Driver Generation Tool for Embedded Systems
- An Automated Flow for Reset Connectivity Checks in Complex SoCs having Multiple Power Domains
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- CHIA: An open-source framework for principled, agentic AI-driven hardware/software co-design research
Latest Articles
- Low-Energy Reduced RISC-V Instruction Subset Processor for Tsetlin Machine Inference at the Edge
- Si-GT: Fast Interconnect Signal Integrity Analysis For Integrated Circuit Design Via Graph Transformers
- Hardware Mechanisms to Dynamically Throttle AI Performance
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers