CHIMERA: A Flexible and Scalable 3.1 TOPS/W AI-MCU with Transformer Accelerator and 563 Gb/s Shared-L2 Memory Subsystem with QoS Guarantees
By Lorenzo Leone * , Philip Wiese *, Davide Rossi †‡, Gamze Islamoglu *, Francesco Conti †, Michael Rogenmoser *, Luca Benini *†
* ETH Zurich, Zurich, Switzerland,
† Universita di Bologna, Bologna, Italy,
‡ Chips-IT, Pavia, Italy
Abstract
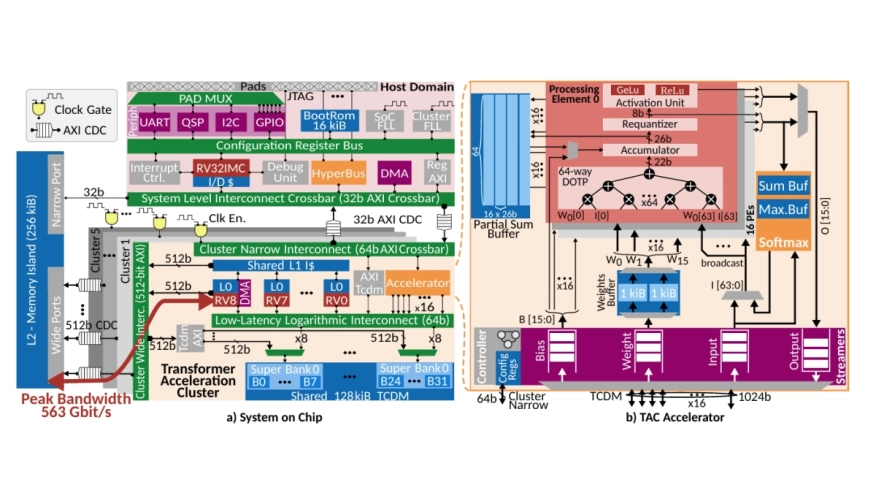
We present Chimera, a flexible and scalable Microcontroller Unit (MCU) designed to accelerate real-time inference of rapidly evolving transformer-based models at the ultra-low-power edge (hundred of mW). The chip, implemented in 22 nm FDX technology, integrates a transformer accelerator tightly coupled within a compute cluster featuring nine general-purpose RV32IMA cores. Scalability extends to the memory hierarchy through a novel L2 memory island subsystem, which enables data sharing across multiple clusters while delivering 563 Gb/s aggregate bandwidth. The L2 subsystem enforces quality-of-service guarantees for latency-critical traffic, achieving up to 16x latency reduction. Chimera achieves peak energy and area efficiencies of 3.1 TOPS/W and 281 GOPS/mm2, demonstrating 1.37x higher energy efficiency and up to 100x higher area efficiency compared to State of the Art (SoA) SoCs. Compared to SoA standalone accelerators, Chimera achieves comparable energy efficiency and up to 1.8x higher area efficiency.
To read the full article, click here
Related Semiconductor IP
- DSP-Based 112G SerDes
- XTAL oscillator in TSMC-7nm
- GPU
- V-by-One Verification IP
- AI model compression IP
Related Articles
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding