aTENNuate: Optimized Real-time Speech Enhancement with Deep SSMs on RawAudio
By Yan Ru Pei, Ritik Shrivastava, FNU Sidharth (BrainChip)
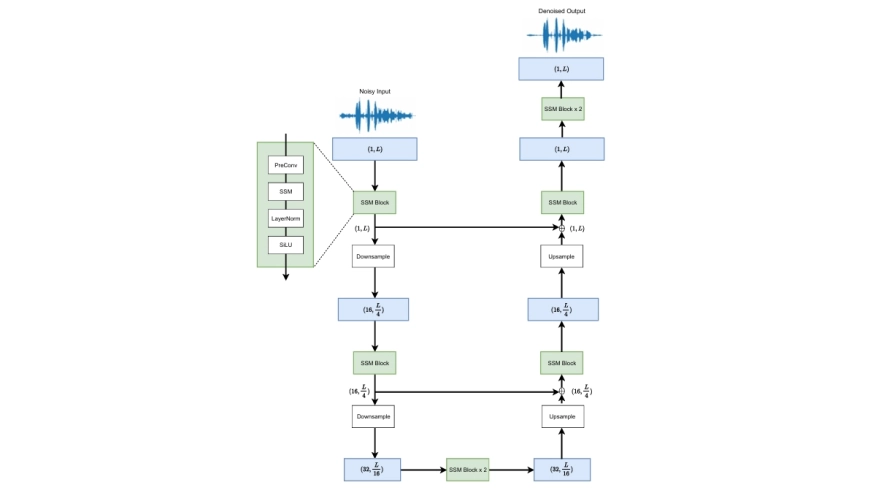
Abstract
We present aTENNuate, a simple deep state-space autoencoder configured for efficient online raw speech enhancement in an end-to-end fashion. The network’s performance is primarily evaluated on raw speech denoising, with additional assessments on tasks such as super-resolution and de-quantization. We benchmark aTENNuate on the VoiceBank + DEMAND and the Microsoft DNS1 synthetic test sets. The network outperforms previous real-time denoising models in terms of PESQ score, parameter count, MACs, and latency. Even as a raw waveform processing model, the model maintains high fidelity to the clean signal with minimal audible artifacts. In addition, the model remains performant even when the noisy input is compressed down to 4000Hz and 4 bits, suggesting general speech enhancement capabilities in low-resource environments.
keywords: state-space models, autoencoder, denoising, super-resolution, de-quantization
To read the full article, click here
Related Semiconductor IP
Related Articles
- ASIC Implementation of a Speech Detector IP-Core for Real-Time Speaker Verification
- A Realtime 1080P30 H.264 Encoder System on a Zynq Device
- Understanding the Deployment of Deep Learning algorithms on Embedded Platforms
- Real-Time ESD Monitoring and Control in Semiconductor Manufacturing Environments With Silicon Chip of ESD Event Detection
Latest Articles
- Design and Development of a Neuromorphic Silicon Suite: PVT Sensing, Stochastic LIF Inference, On-Chip STDP Learning, and Crossbar Programming
- LLM4RTL: Tool-Assisted LLM for RTL Generation
- Towards Delta Aware Training: Efficient DNN Weight Storage for Resource-Constrained FPGAs
- CHERI-D: Secure and efficient inline object ID for CHERI temporal memory safety
- AIA: A 16nm Multicore SoC for Approximate Inference Acceleration Exploiting Non-normalized Knuth-Yao Sampling and Inter-Core Register Sharing