An FPGA Implementation of Displacement Vector Search for Intra Pattern Copy in JPEG XS
By Qiyue Chen, Yao Li, Jie Tao, Song Chen, Li Li, Dong Liu
University of Science and Technology of China, Hefei, China
Abstract
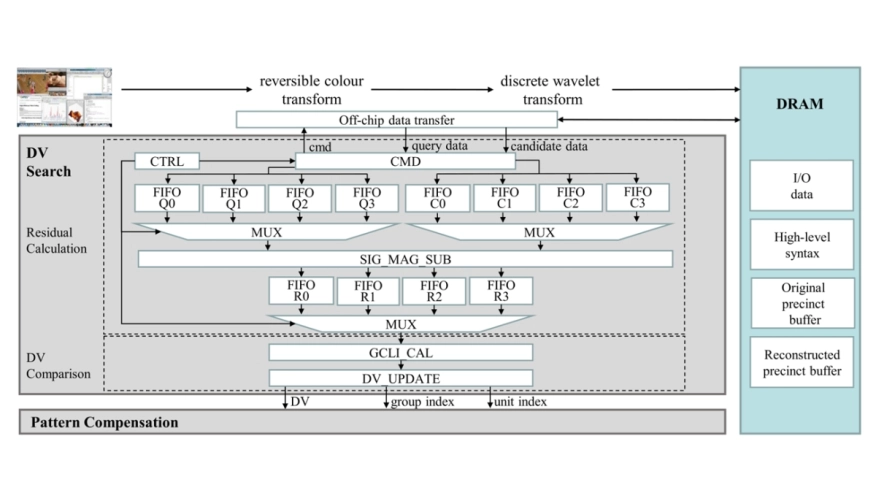
Recently, progress has been made on the Intra Pattern Copy (IPC) tool for JPEG XS, an image compression standard designed for low-latency and low-complexity coding. IPC performs wavelet-domain intra compensation predictions to reduce spatial redundancy in screen content. A key module of IPC is the displacement vector (DV) search, which aims to solve the optimal prediction reference offset. However, the DV search process is computationally intensive, posing challenges for practical hardware deployment. In this paper, we propose an efficient pipelined FPGA architecture design for the DV search module to promote the practical deployment of IPC. Optimized memory organization, which leverages the IPC computational characteristics and data inherent reuse patterns, is further introduced to enhance the performance. Experimental results show that our proposed architecture achieves a throughput of 38.3 Mpixels/s with a power consumption of 277 mW, demonstrating its feasibility for practical hardware implementation in IPC and other predictive coding tools, and providing a promising foundation for ASIC deployment.
To read the full article, click here
Related Semiconductor IP
- JPEG XS - Low-Latency Video
- Visually LossLess decompression hardware RTL core that complies with ISO/IEC-21122-1 (JPEG XS)
- Visually LossLess compression hardware RTL core that complies with ISO/IEC-21122-1 (JPEG XS)
- JPEG XS compression IP core for HD - Max fps: 480 - Color sampling: 4:2:2 / 4:0:0
- JPEG XS compression IP core for HD - Max fps: 120- Color sampling: 4:4:4 / 4:2:2 / 4:0:0
Related Articles
- An 800 Mpixels/s, ~260 LUTs Implementation of the QOI Lossless Image Compression Algorithm and its Improvement through Hilbert Scanning
- The rise of FPGA technology in High-Performance Computing
- Hardware vs. Software Implementation of Warp-Level Features in Vortex RISC-V GPU
- An AUTOSAR-Aligned Architectural Study of Vulnerabilities in Automotive SoC Software
Latest Articles
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding
- Vectorizing Quantum Control: A RISC-V Vector Extension Architecture for Scalable Qubit Systems
- FlexViT: A Flexible FPGA-based Accelerator for Edge Vision Transformers