Towards Delta Aware Training: Efficient DNN Weight Storage for Resource-Constrained FPGAs
By David Peter Federl, Lukas Einhaus, Andreas Erbslöh, Gregor Schiele
University Duisburg-Essen, Germany
Abstract
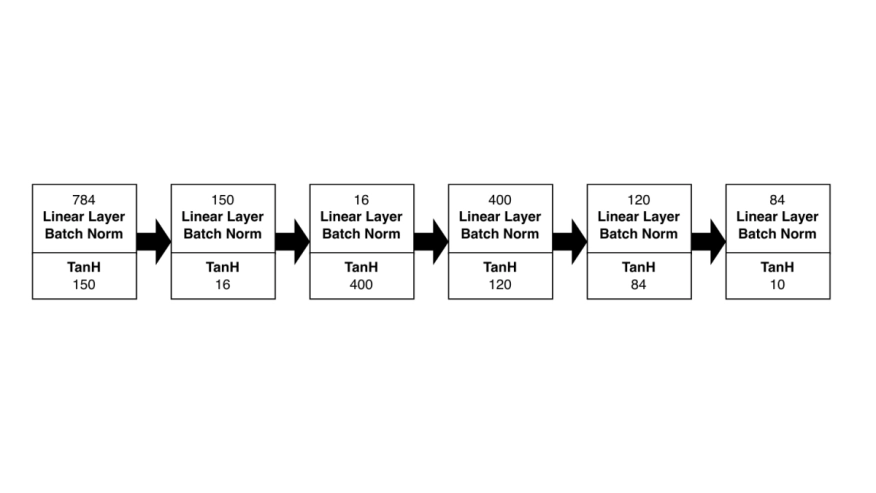
The deployment of embedded deep neural networks on resource-constrained field programmable gate arrays (FPGAs) is challenging due to limited memory and computational capacities. We introduce a new compression technique to reduce the memory footprint by saving weights in deltas with lower bitwidth and training the network to cope with compressed deltas. Two delta schemes are investigated: consecutive deltas and deltas with a fixed-reference value. We evaluate both on the FashionMNIST data set with a multi-layer-perceptron. The results indicate that fixed-reference delta compression outperforms the consecutive variant, achieving a validation accuracy of approximately 78.6 %, with 4 bit weight deltas, representing an accuracy loss of roughly 8.3 % compared to a fixed-point network with 8 bit. Our specialized hardware accelerator with a delta-compressed multiply-and-accumulate operator compresses weights by nearly 50 % and achieves a maximum throughput of 7.992M MACs/s on an AMD Spartan-7 S15 FPGA.
Keywords: embedded deep neural networks, resource-constrained, field programmable gate array, hardware accelerator, fixpoint-arithmetic, quan tization aware training, weight compression
To read the full article, click here
Related Semiconductor IP
- NPU IP Core for Edge
- Highly scalable inference NPU IP for next-gen AI applications
- 4-/8-bit mixed-precision NPU IP
- PowerVR Neural Network Accelerator - The ultimate solution for high-end neural networks acceleration
- PowerVR Neural Network Accelerator - The perfect choice for cost-sensitive devices
Related Articles
- FastPath: A Hybrid Approach for Efficient Hardware Security Verification
- Efficient Hardware-Assisted Heap Memory Safety for Embedded RISC-V Systems
- Bare-Metal RISC-V + NVDLA SoC for Efficient Deep Learning Inference
- A Resource-Driven Approach for Implementing CNNs on FPGAs Using Adaptive IPs
Latest Articles
- SEAM-V: A Hybrid-Decoupled RISC-V Vector Processor with Backend-Visible EP Context for Sustained Vector Throughput
- New Number Formats for FFT IP Cores in Optical OFDM Transceivers
- Reducing Power Consumption of Embedded Dynamic Memories with ECCs
- NIFA: Nonlinear IMC enhanced FPGA for efficient ML inference
- A 32-channel event-based bio-signal analog front-end with adaptive delta and pulse frequency encoding