Benchmarking an NPU at Scale

With every SDK release, Quadric automatically recompiles and re-profiles the entire model zoo across a broad sweep of hardware configurations. The results land in DevStudio for any SoC architect to explore — no sales call, no handpicked numbers.
With every Chimera™ SDK release, something quietly industrial happens: the entire 300+ model zoo gets automatically recompiled and re-profiled across a broad sweep of hardware configurations and the results land in DevStudio in the process. No one is hand-typing FPS numbers into a slide or running a single model on a single configuration to cherry-pick for a datasheet. The whole zoo moves forward together, release by release, in front of anyone who wants to look.
“Port Once” is Not Enough
The traditional vendor model zoo is a curiously stale artifact: a dozen or two models get ported once, benchmarked on one silicon configuration, and the resulting FPS number gets stamped onto a product brief. Eventually the compiler evolves, a new core configuration ships, a new SoC customer wants to see the data on their target memory configuration, and the published number gradually drifts away from reality.
For an SoC architect, this isn't just useless, it's actively harmful. The number on the brief doesn't match the chip they're planning to license so their engineering team has to re-run the benchmark themselves: usually under NDA, on a shrunken set of models, and only after a sales call.
And then for the vendor, the zoo rots between releases. Every new compiler optimization, core configuration, and model added to the zoo multiplies the manual effort required to keep the numbers fresh until eventually the math stops working and the zoo stops growing. We've written before about how graph compilers are still early in their maturity curve and will keep delivering performance gains release after release, but that only remains visible if the benchmark infrastructure keeps up with the compiler.
Dimensioning an NPU, Honestly
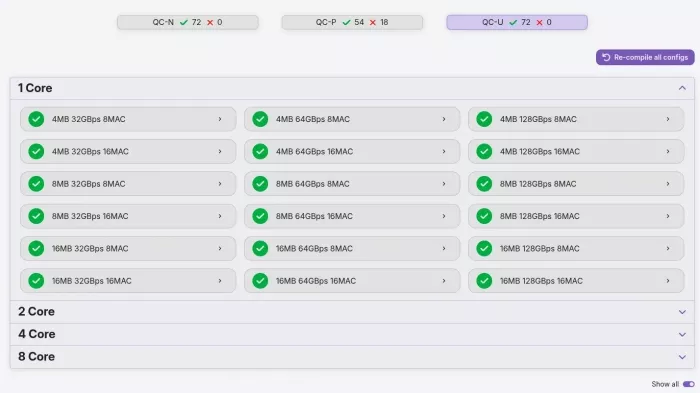
Pass/fail status: every configuration, every product family.
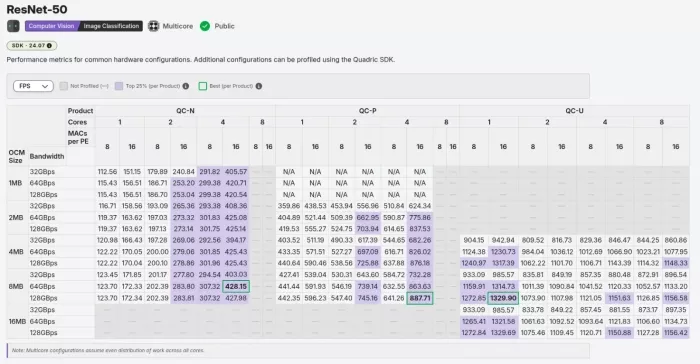
Performance across product families, core counts, MAC widths, L2 memory sizes, and bandwidths. Visit DevStudio directly for live data.
With Quadric's DevStudio, SoC sizing using the Chimera™ GPNPU is made concrete.
The greens answer the immediate question: which configurations are safe choices for my SoC? The performance matrix answers the next one: how fast do each of them go?
The process for getting information is clean:
- Pick the model that matters for your product (a vision backbone, a YOLO variant, a speech or OCR model, or anything else in the zoo)
- Pick a target Chimera™ product family: QC-Nano for tight power budgets, QC-Perform for mid-range, QC-Ultra for headroom
- Select L2 memory size, MACs per PE, core count, and bandwidth
From there, you can read the FPS directly and compare it to whatever peak TOPS number another vendor quoted last week, and it's the same data our applications team uses to recommend a configuration internally. It isn't gated behind a meeting. And that performance is a floor, not a ceiling: the SDK can profile additional configurations on demand.
Because every number in DevStudio comes out of the same pipeline, there's no room for a "we got this on a good day" run or a cherry-picked configuration that flatters one model: the matrix is the matrix. It's also how we can credibly show the compiler getting better release-over-release: the same models, the same configurations, every time.
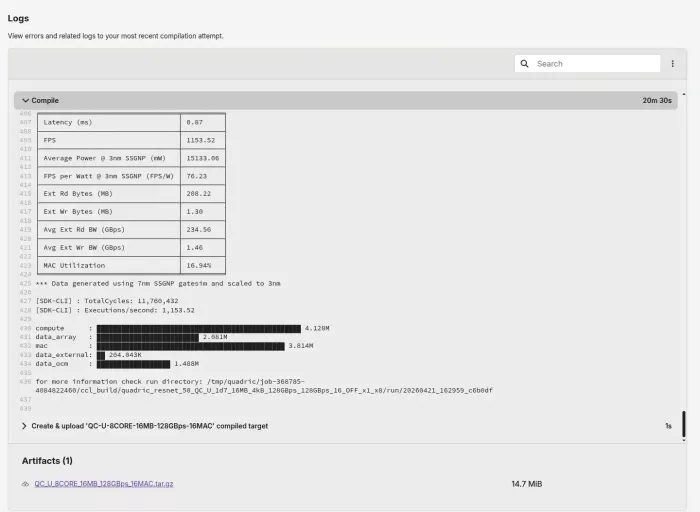
Job log and artifact: one model, one configuration.
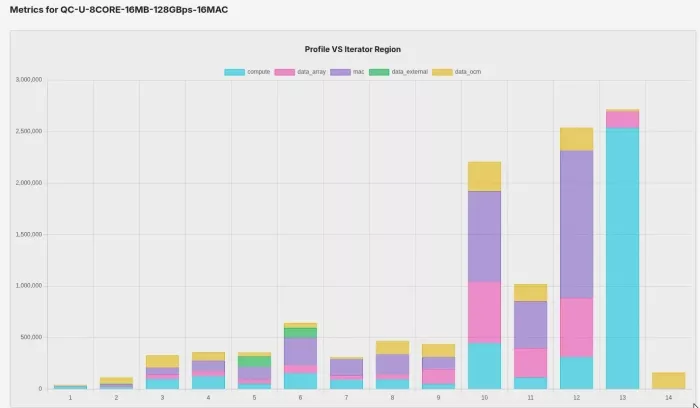
Per-region profile: where compute, MAC, and memory-movement time go across the graph.
What you're looking at is CI/CD applied to NPU model compilation: jobs with logs and artifacts, matrix-swept across a parametric configuration space, with detailed metrics for each hardware configuration, run on every release. The pattern is the same one every serious software product uses to build and test at scale. What's unique to Quadric is that we apply it in this domain, at this scale, out in the open for customers to see.
What Everybody Else is Doing
We've done the homework on the rest of the NPU and edge-AI landscape, and there are three things we do that rarely show up together anywhere else: self-serve access, always-available browsing, and numbers that reflect the latest SDK.
- Among NPU IP licensors — the vendors most directly comparable to Quadric — there is nothing self-serve. Per-model, per-configuration numbers come out of an NDA-gated engagement with the vendor's applications team (assuming they come out at all). If they're lucky enough to even get those numbers, the customer ends up with a one-time snapshot that can't be re-checked against the next compiler release.
- Among edge-AI silicon vendors who do publish, the surfaces are GitHub model zoos and developer-portal model explorers, with dozens of models against a small number of fixed silicon SKUs and release cadences ranging from continuous-GitHub to roughly annual. None of them (to our knowledge) let a user self-serve a parametric IP configuration sweep on the latest release.
- Among data-center AI silicon vendors, one or two publish excellent per-model LLM matrices on a handful of fixed chips, updated continuously on GitHub. That's a real self-serve benchmark culture, it's just not an edge-NPU-IP configuration space.
The differentiator isn't "nobody publishes"; a few vendors do and their numbers are credible. The differentiator is combining zoo size, a parametric configuration space, and release-coupled refresh into one always-available, self-serve surface, so the numbers an SoC architect sees today are the numbers the compiler produced on the latest release and not a snapshot from a sales deck.
Explore NPU IP:
- GPNPU Processor IP - 32 to 864TOPs
- GPNPU Processor IP - 16 to 108 TOPs
- GPNPU Processor IP - 4 to 28 TOPs
See it for Yourself
The fastest way to understand what Quadric's approach means for your SoC is to open DevStudio, pick a model you care about, and look at the configuration matrix yourself. If the one you're planning isn't there, you can profile it with the Chimera SDK, and if the model you're planning isn't in the zoo, you can upload it.
Check out the Quadric DevStudio benchmarks to explore a sample of the full model zoo or browse the model catalog to see the models Quadric validates on every SDK release.
Building infrastructure like this (a parametric matrix of thousands of compile+profile jobs refreshed every release, surfaced as something an SoC architect can actually use) is the sort of work we do a lot of. If that sounds like something you enjoy working on, we'd like to hear from you.
Related Semiconductor IP
- GPNPU Processor IP - 32 to 864TOPs
- GPNPU Processor IP - 16 to 108 TOPs
- GPNPU Processor IP - 4 to 28 TOPs
- NPU
- RISC-V-Based, Open Source AI Accelerator for the Edge
Related Blogs
- Find Everything You Need to Build an Advanced PCI Express 4.0 Solution in One Booth - Visit Cadence at PCI-SIG DevCon 2015
- Cadence Implementation Flow for an ARM Cortex-A73 at 10nm
- Arm and Arteris IP present AI NPU and ISO 26262 integration together at ICCAD China
- Arm Ethos-N78 NPU: Unprecedented Machine Learning Capability at your Fingertips
Latest Blogs
- Crypto mining SoC unearths a need for custom IP
- Moving to AMBA® 5? Your AMBA® 4 IP Can Still Come With You
- Hitting the Memory Wall:Why Cache Miss Tolerance Defines CPU Performance Now
- Why 10BASE-T1S Automotive Ethernet SoC Verification Needs More Than Simulation?
- How Cadence and TSMC Are Accelerating AI Silicon Design at Advanced Nodes