Microarchitectural Co-Optimization for Sustained Throughput of RISC-V Multi-Lane Chaining Vector Processors
By Weiying Wang, Zhiwei Zhang
Institute of Automation, Chinese Academy of Sciences School of Artificial Intelligence, University of Chinese Academy of Sciences, Beijing China
Abstract
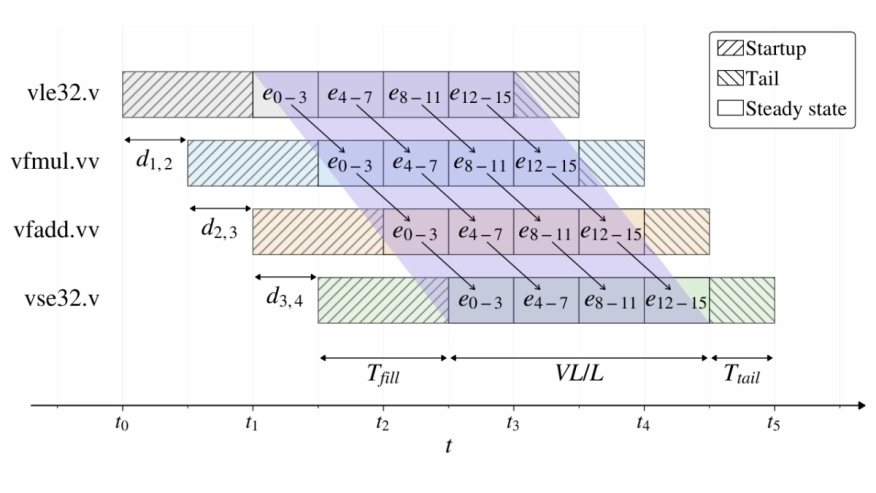
Modern RISC vector processors rely on the synergy of multi-lane parallelism and chaining to achieve high sustained throughput, yet their achieved performance often falls substantially short of the theoretical performance bound due to microarchitectural inefficiencies. In this work, we take the open-source RVV processor Ara as the target platform and analyze the sources of its sustained-throughput loss and optimize the design accordingly. We first establish an ideal multi-lane chaining execution model as a microarchitectural reference for the ideal steady-state progression of the vector backend. Based on this model, we attribute Ara's key bottlenecks to inefficiencies along three critical execution paths: memory-side inefficiencies in data supply and transaction issuance, control-side inefficiencies caused by conservative dependence management and issue control, and operand-delivery inefficiencies caused by access conflicts and result-propagation overhead. To address these bottlenecks, we propose a coordinated set of microarchitectural optimizations. Experimental results show that, without increasing raw memory bandwidth or changing the main processor configuration, Ara-Opt achieves a geometric-mean speedup of 1.33x over baseline Ara. Under roofline-based normalization, the geometric-mean gap-closed ratio reaches 12.2%. In particular, scal, axpy, ger, and gemm achieve speedups of approximately 2.41x, 1.60x, 1.52x, and 1.42x, with corresponding gap-closed ratios of 93.7%, 88.9%, 78.3%, and 59.3%, respectively. These results show that the proposed method can effectively recover sustained-throughput capability lost to microarchitectural inefficiencies in Ara under essentially unchanged hardware resource constraints, and move the implementation points of regular streaming and high-throughput workloads significantly closer to the theoretical performance bound.
Index Terms — RISC-V Vector Extension, Sustained Throughput, Multi-Lane Chaining, Microarchitectural Co-Optimization
To read the full article, click here
Related Semiconductor IP
Related Articles
- Efficient Verification of RISC-V processors
- Design and implementation of a hardened cryptographic coprocessor for a RISC-V 128-bit core
- DRsam: Detection of Fault-Based Microarchitectural Side-Channel Attacks in RISC-V Using Statistical Preprocessing and Association Rule Mining
- Timing Fragility Aware Selective Hardening of RISCV Soft Processors on SRAM Based FPGAs
Latest Articles
- Microarchitectural Co-Optimization for Sustained Throughput of RISC-V Multi-Lane Chaining Vector Processors
- RISC-V Functional Safety for Autonomous Automotive Systems: An Analytical Framework and Research Roadmap for ML-Assisted Certification
- Emulation-based System-on-Chip Security Verification: Challenges and Opportunities
- A 129FPS Full HD Real-Time Accelerator for 3D Gaussian Splatting
- SkipOPU: An FPGA-based Overlay Processor for Large Language Models with Dynamically Allocated Computation