Why Vision LLMs Force A Rethink Of Edge AI Hardware

As vision-centric large language models move on-device, performance measured in raw TOPS is no longer enough. Architectures need to be built around real workloads, memory behavior, and sustained utilization, especially at the edge.
Vision LLMs are changing the edge AI equation
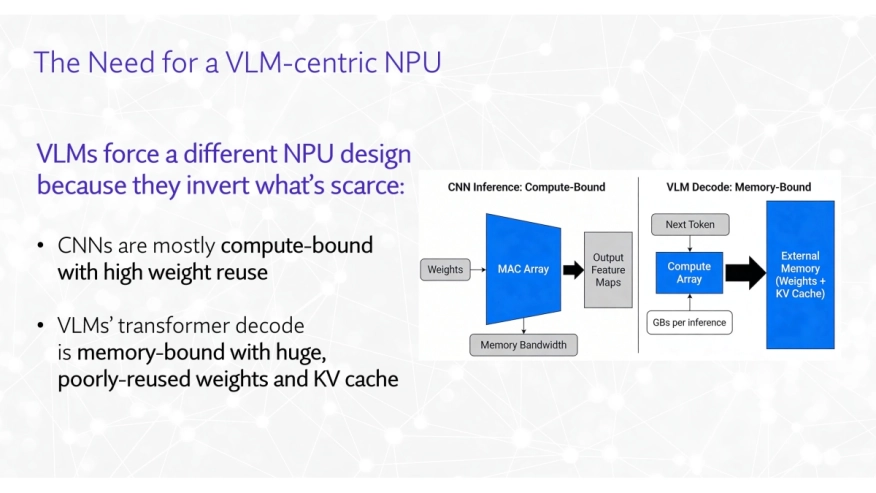 For the last decade, most edge AI silicon has been built to do one job extremely well: run convolutional networks for image classification, detection, and basic segmentation. That design point is becoming less sufficient as multimodal models move from research into commercial edge systems.
For the last decade, most edge AI silicon has been built to do one job extremely well: run convolutional networks for image classification, detection, and basic segmentation. That design point is becoming less sufficient as multimodal models move from research into commercial edge systems.
Vision LLMs fuse perception, semantics, and reasoning in a single pipeline. They can understand scenes, answer questions about what they see, summarize events across time, and increasingly help determine what to do next. Cameras, vehicles, industrial systems, and medical platforms are increasingly demanding these capabilities locally rather than exclusively in the cloud.
Running those models on-device offers clear benefits. Local inference can reduce latency, improve privacy, and lower dependence on network connectivity and cloud inference cost. But it also breaks many of the assumptions behind first-generation edge accelerators.
Why adding more TOPS is not enough
At first glance, running Vision LLMs at the edge can look like a simple scaling problem: take an existing NPU or GPU and add more compute and memory. In practice, teams quickly discover that the bottleneck is often memory traffic and utilization, not theoretical arithmetic throughput.
The first issue is model size. Modern transformer-based systems are measured in billions of parameters, and multimodal systems add visual front ends that convert images or video into tokens for downstream reasoning. The result is a large weight footprint, substantial activations, and growing key/value state, all of which increase memory capacity and memory bandwidth pressure.
The second issue is attention. The underlying scaled dot-product attention mechanism grows roughly quadratically with context, which means longer prompts, richer multimodal context, and larger token counts can quickly overwhelm an edge memory subsystem. Even when peak compute looks adequate on paper, many systems stall because data movement becomes the practical limit.
The third issue is workload irregularity. Vision LLMs are not just transformers with images attached. They combine visual encoders, transformer layers, feed-forward blocks, normalization, vector operations, and output heads, all with different shapes and reuse patterns. In internal evaluations on modern multimodal graphs, models that appear efficient on isolated benchmarks often show poor utilization once longer contexts and full visual pipelines are enabled.
Explore NPU IP:
- Neural engine IP - Tiny and Mighty
- NPU IP Core for Edge
- NPU IP Core for Mobile
- NPU IP Core for Data Center
A more realistic optimization stack
One of the more useful takeaways from Expedera’s Vision LLM research is that edge deployment has to be optimized across three layers: model architecture, system-level scheduling, and dedicated hardware support. That framing matters because it shifts the discussion away from a single-chip-solution mindset and toward hardware-software co-design.
At the model level, teams can consider alternatives such as hybrid or non-transformer designs, distilled variants, and embodied-agent models that retain key capabilities at lower cost. At the software level, quantization, tiling methods such as FlashAttention, and speculative decoding help reduce memory pressure and improve latency. But those techniques only go so far if the underlying architecture still assumes regular layer behavior and layer-by-layer execution.
That is where dedicated hardware support becomes important. The right accelerator needs to be evaluated not only on peak throughput, but on how well it sustains utilization across real multimodal graphs while controlling external memory traffic.
What typical NPUs get wrong
Many NPUs in the field today were designed around the realities of CNN-heavy edge vision. Implicitly, they assume relatively regular layer shapes, predictable tiling behavior, and a manageable balance between weights, activations, and on-chip memory.
Those assumptions break down on Vision LLM workloads. Strict layer-by-layer execution tends to spill activations into external memory more often, and fixed execution patterns are less efficient when the graph alternates between vision encoding, attention, feed-forward, and vector-heavy operations. As context windows grow and multimodal fusion becomes richer, key/value state and activation movement become an outsized contributor to power and latency.
This is also why peak TOPS is becoming a weaker proxy for delivered edge performance. A design that looks strong on synthetic benchmarks may still perform poorly on actual Vision LLM graphs if it cannot maintain locality and utilization as the workload shifts from stage to stage.
Packets: designing around the workload
One response to this problem is to rethink the unit of execution in hardware. Expedera’s Origin architecture takes that approach, describing it as a packet-based AI processing architecture.
Packets are small, dependency-aware fragments of a neural network that move vertically through the graph, rather than forcing the system to process one complete layer at a time. These packets can be routed through specialized processing resources, reordered with low context-switch overhead, and retired once their activations are no longer needed.
That change in abstraction has several implications. First, it can improve sustained utilization because the hardware is less dependent on every layer matching an ideal execution shape. Second, it can reduce costly external memory movement by allowing intermediate data to be consumed and retired earlier. Third, packetization does not change the underlying mathematics of the model, so it is positioned as an execution strategy rather than a change to network accuracy or model semantics.
Why this matters for Vision LLMs
Vision LLMs are a good stress test for any accelerator because they combine multiple computational personalities into a single inference path. A typical pipeline starts with visual encoding, moves into multimodal reasoning with attention and feed-forward layers, and ends with output generation or action selection.
Those stages do not place the same demands on hardware. Visual front ends reuse patterns familiar from edge vision, but the reasoning path introduces the sequence-heavy, cache-heavy behavior associated with LLMs. Output and fusion stages often lean on vector and support operations that are underserved by hardware tuned only for dense matrix math.
A packet-based architecture is well-suited to that kind of heterogeneity because it can route work through specialized Feed Forward, Attention, and Vector blocks rather than forcing every stage to use the same execution model. More broadly, it reflects a design principle that is likely to matter beyond any one vendor: represent work at a granularity that matches how modern multimodal graphs actually execute.
Implications for chip and system teams
For SoC architects and software teams, several conclusions follow. The first is that the evaluation criteria need to evolve. Peak TOPS and TOPS/W are still useful, but they should be complemented by workload-specific measures such as sustained utilization, external memory transactions, and tail latency on real Vision LLM graphs.
The second is that hardware flexibility matters more than ever. Architectures should be tested against a portfolio that includes legacy CNNs, transformer-based LLMs, diffusion pipelines, and newer multimodal models, because edge products will increasingly need to support all of them over their life cycle.
The third is that hardware and software can no longer be treated as separate deliverables. For example, Expedera’s stack includes a compiler, estimator, scheduler, and quantizer, alongside the core NPU architecture, reinforcing the broader lesson that efficient Vision LLM deployment depends on end-to-end co-design.
Designing around real workloads
Vision LLMs will continue to move toward the edge because the product value is too strong to ignore. Devices that can understand what they see, reason over local context, and respond without sending everything to the cloud will offer better latency, stronger privacy, and often lower operating costs.
The core hardware question, then, is no longer how many TOPS can fit inside a given power and area budget. It is whether an architecture is built around real multimodal workload behavior, especially memory movement, activation lifetimes, utilization under irregular graphs, and the software needed to schedule all of it effectively.
Architectures such as Expedera’s packet-based Origin NPU point to one possible answer: represent work the way modern neural networks actually execute, then build compute, memory, and software around that reality. For teams building the next generation of edge silicon, that workload-first mindset may matter more than any single peak performance number.
Related Semiconductor IP
- Neural engine IP - Tiny and Mighty
- NPU IP Core for Edge
- NPU IP Core for Mobile
- NPU IP Core for Data Center
- NPU
Related Blogs
- Why Physical AI Needs a New Generation of Embedded Memory
- Rethinking Edge AI Interconnects: Why Multi-Protocol Is the New Standard
- The Rise of Physical AI and Robotics: Why Hardware-Based Security is Non-Negotiable
- Enhancing Edge AI with the Newest Class of Processor: Tensilica NeuroEdge 130 AICP
Latest Blogs
- World's First Standards-Compliant 112G PHY IP for Linear Optics: A Turning Point for AI Interconnects
- One Key for Every Door: How Aliro Extends the UWB Digital Key Beyond the Car
- Reprogrammable Post-Quantum Security for SoCs: Why Crypto-Agility Matters
- Designing the Beam Steering Core for a C-Band AESA: A Look at VSI's VBF0644 GaAs Beamformer IC
- Secure Boot for embedded systems: Building a complete chain of trust