Can Your NPU Run DOOM? Chimera Can.
Is your NPU DOOMed? Quadric's Chimera GPNPU runs every AI model — and a complete DOOM engine. Find out why Quadric is different.
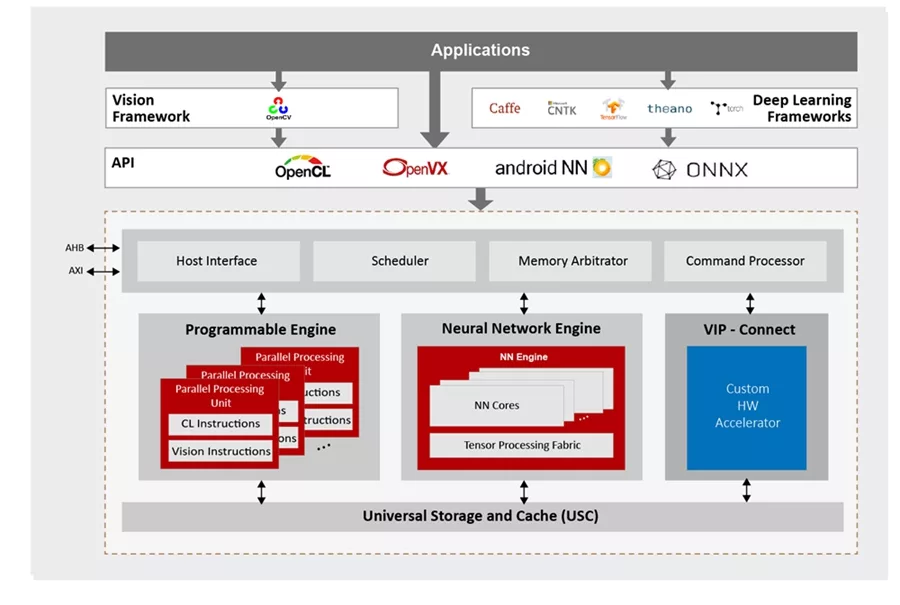
The VIP9000 family offers programmable, scalable and extendable solutions for markets that demand real time and low power AI devi…
The VIP9000 family offers programmable, scalable and extendable solutions for markets that demand real time and low power AI devices. VIP9000 Series’ patented Neural Network engine and Tensor Processing Fabric deliver superb neural network inference performance with industry-leading power efficiency (TOPS/W) and area efficiency (mm2/W). The VIP9000’s scalable architecture, ranging from 0.5TOPS to 20TOPS, enables AI capability for a wide range of applications, from wearable and IoT devices, IP Cam, surveillance cameras, smart home & appliances, mobile phones and laptops to automotive (ADAS, autonomous driving) and edge servers. In addition to neural network acceleration, VIP9000 Series are equipped with Parallel Processing Units (PPUs), which provide full programmability along with conformance to OpenCL 3.0 and OpenVX 1.2.
VIP9000 Series IP supports all popular deep learning frameworks (TensorFlow, TensorFlow Lite, PyTorch, Caffe, DarkNet, ONNX, Keras, etc.) and natively accelerates neural network models through optimization techniques such as quantization, pruning, and model compression. AI applications can easily port to VIP9000 platforms through offline conversion by Vivante’s ACUITYTM Tools SDK or through run-time interpretation with Android NN, NNAPI Delegate, ARMNN, or ONNX Runtime.
Note: some files may require an NDA depending on provider policy.

NPU IP for AI Vision and AI Voice is a NPU IP core from VeriSilicon Microelectronics (Shanghai) Co., Ltd. listed on Semi IP Hub.
Engineers should review the overview, key features, supported foundries and nodes, maturity, deliverables, and provider information before shortlisting this NPU IP.
Yes. Buyers can compare this product with similar semiconductor IP cores or IP families based on category, provider, process options, and structured technical specifications.