Can Your NPU Run DOOM? Chimera Can.
Is your NPU DOOMed? Quadric's Chimera GPNPU runs every AI model — and a complete DOOM engine. Find out why Quadric is different.
The inference neural processing unit (NPU) IP is suitable for high-performance edge devices including automotive, cameras, and mo…
The state-of-the-art inference neural processing unit (NPU) IP is suitable for high-performance edge devices including automotive, cameras, and more. ENLIGHT Pro is meticulously engineered to deliver enhanced flexibility, scalability, and configurability, enhancing overall efficiency in a compact footprint. ENLIGHT Pro supports the transformer model, a key requirement in modern AI applications, particularly Large Language Models (LLMs). LLMs are instrumental in tasks such as text recognition and generation, trained using deep learning techniques on extensive datasets. The automotive industry is expected to adopt LLMs to offer instant, personalized, and accurate responses to customers' inquiries.
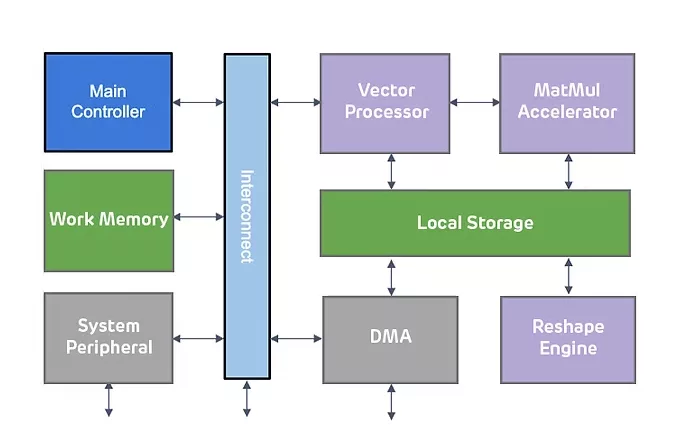
ENLIGHT Pro sets itself apart by achieving 4096 MACs/cycle for an 8-bit integer, quadrupling the speed of ENLIGHT Classic, and operating at up to 1.0GHz on a 14nm process node. It offers performance ranging from 8 TOPS (Terra Operations per Second) to hundreds of TOPS, optimized for flexibility and scalability. ENLIGHT Pro supports tensor shape transformation operations, including slicing, splitting, and transposing, and supports a wide variety of data types --- integer 8, 16, 32, and floating point (FP) 16 and 32 --- to ensure flexibility across computational tasks. The vector processor achieves a 16 floating point 16 MACs/cycle, and includes a 32x2 KB vector register file (VRF). Additionally, single-core, dual-core, and quad-core with scalable task mappings such as multiple models, data parallelism, and tensor parallelism are available.
ENLIGHT Pro incorporates a RISC-V CPU vector extension with custom instructions. This includes support for Softmax and local storage access, enhancing its overall flexibility. It comes with a software toolkit that supports widely used network formats like ONNX (PyTorch), TFLite (TensorFlow), and CFG (Darknet). ENLIGHT SDK streamlines the conversion of floating-point networks to integer networks through a network compiler and generates NPU commands and network parameters via a network compiler.
Note: some files may require an NDA depending on provider policy.

Highly scalable inference NPU IP for next-gen AI applications is a NPU IP core from OPENEDGES Technology, Inc. listed on Semi IP Hub.
Engineers should review the overview, key features, supported foundries and nodes, maturity, deliverables, and provider information before shortlisting this NPU IP.
Yes. Buyers can compare this product with similar semiconductor IP cores or IP families based on category, provider, process options, and structured technical specifications.