Ceva-NeuPro-M is a scalable NPU architecture, ideal for transformers, Vision Transformers (ViT), and generative AI applications, with an exceptional power efficiency of up to 3500 Tokens-per-Second/Watt for a Llama 2 and 3.2 models
The Ceva-NeuPro-M Neural Processing Unit (NPU) IP family delivers exceptional energy efficiency tailored for edge computing while offering scalable performance to handle AI models with over a billion parameters. Its innovative architecture, which has won multiple awards, introduces significant advancements in power efficiency and area optimization, enabling it to support massive machine-learning networks, advanced language and vision models, and multi-modal generative AI. With a processing range of 4 to 200 TOPs per core and leading area efficiency, the Ceva-NeuPro-M optimizes key AI models seamlessly. A robust tool suite complements the NPU by streamlining hardware implementation, model optimization, and runtime module composition.
The Solution
The Ceva-NeuPro-M NPU IP family is a highly scalable, complete hardware and software IP solution for embedding high performance AI processing in SoCs across a wide range of edge AI applications.
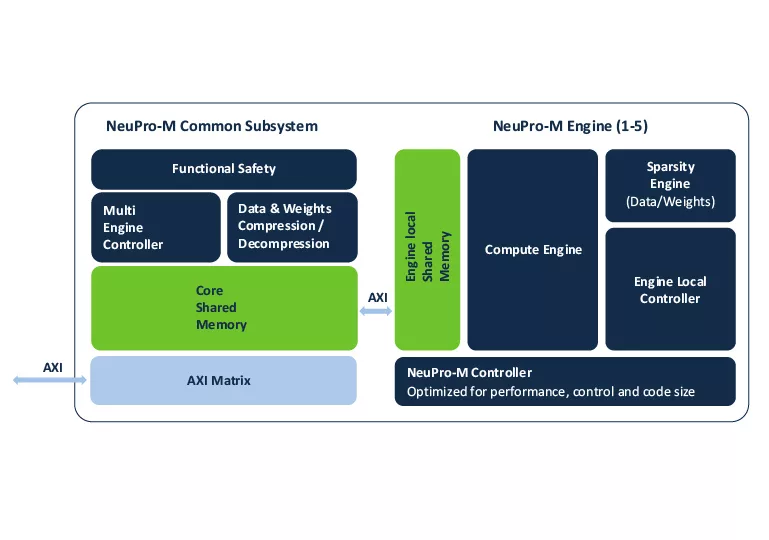
The heart of the NeuPro-M NPU architecture is the computational unit. Scalable from 4 to 20 TOPs, a single computational unit comprises a multiple-MAC parallel neural computing engine, activation and sparsity control units, an independent programable vector-processing unit, plus local shared L1 memory and a local unit controller. A core may contain up to eight of these computational units, along with a shared Common Subsystem comprising functional-safety, data-compression, shared L2 memory, and system interfaces.
These NPU cores may be grouped into multi-core clusters to reach performance levels in excess of 2000 TOPS.