Can Your NPU Run DOOM? Chimera Can.
Is your NPU DOOMed? Quadric's Chimera GPNPU runs every AI model — and a complete DOOM engine. Find out why Quadric is different.
Whether deployed in-cabin for driver distraction or in the driver assistance system (ADAS) stack for object recognition and point…
Whether deployed in-cabin for driver distraction or in the advanced driver assistance system (ADAS) stack for object recognition and point cloud processing, AI forms the backbone of the future of safer, smarter cars.
AI Demands Higher Performance
Auto makers are adding more AI, including advanced LLM and multimodal capabilities, as they enable safety and usability use cases such as autonomous driving/ADAS, driver attention monitoring, passenger detection, and infotainment. While local inference is essential for all safety-critical systems, LLMs may be 20 to 50X larger than more traditional AI networks. Automotive inference capabilities on today's processors are already limited, and automakers are looking for alternative, more efficient architectures for next generation systems.
Ideal Processing Architecture
Origin Evolution™ for Automotive offers out-of-the-box compatibility with popular LLM and CNN networks. Attention-based processing optimization and advanced memory management ensure optimal AI performance across a variety of today’s standard and emerging neural networks. Featuring a hardware and software co-designed architecture, Origin Evolution for Automotive scales to 96 TFLOPS in a single core, with multi-core performance to PetaFLOPs.
Innovative Architecture
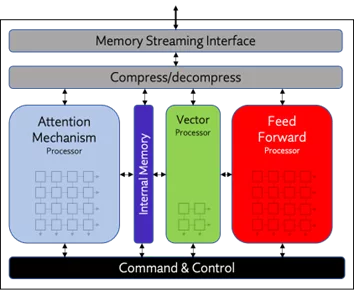
Origin Evolution uses Expedera’s unique packet-based architecture to achieve unprecedented NPU efficiency. Packets, which are contiguous fragments of neural networks, are an ideal way to overcome the hurdle of large memory movements and differing network layer sizes, which are exacerbated by LLMs. Packets are routed through discrete processing blocks, including Feed Forward, Attention, and Vector, which accommodate the varying operations, data types, and precisions required when running different LLM and CNN networks. Origin Evolution includes a high-speed external memory streaming interface that is compatible with the latest DRAM and HBM standards.
Specifications
| Compute Capacity | up to 48 FP16 MACs |
| Multi-tasking | Run Simultaneous Jobs |
| Example Networks Supported | Llama2, Llama3, ChatGLM, DeepSeek, Mistral, Qwen, MiniCPM, Yolo, MobileNet, and many others, including proprietary/black box networks |
| Example Performance | 261 tokens per second, DeepSeek v3 token generation, 64 TFLOPS engine, batch size of 512, 256 GB/s external peak bandwith, 4.391W peak power consumption. Specified in TSMC 7nm, 1 GHz system clock, no sparsity/compression/pruning applied (though supported) |
| Layer Support | Standard NN functions, including Transformers, Conv, Deconv, FC, Activations, Reshape, Concat, Elementwise, Pooling, Softmax, others. Support for custom operators. |
| Data types | FP16/FP32/INT4/INT8/INT10/INT12/INT16 Activations/Weights |
| Quantization | Software toolchain supports Expedera, customer-supplied, or third-party quantization. Mixed precision supported. |
| Latency | Deterministic performance guarantees, no back pressure |
| Frameworks | Hugging Face, Llama.cpp, PyTorch, TVM, ONNX. Tensor Flow and others supported |
| Safety | ASIL-B readiness, ISO 9001:2015 |
Note: some files may require an NDA depending on provider policy.

NPU IP Core for Automotive is a NPU IP core from Expedera listed on Semi IP Hub.
Engineers should review the overview, key features, supported foundries and nodes, maturity, deliverables, and provider information before shortlisting this NPU IP.
Yes. Buyers can compare this product with similar semiconductor IP cores or IP families based on category, provider, process options, and structured technical specifications.