Overview
PMCC_XCM_64x64_D IP block is a low-power array of 1GHz clocked Cross-Correlator cells that are synchronously acquiring two sets of 64x2-bit data streams which are derived by digitizing IF signals at a 2-bit precision. The IP block is cross-correlating and preparing the data for further processing.
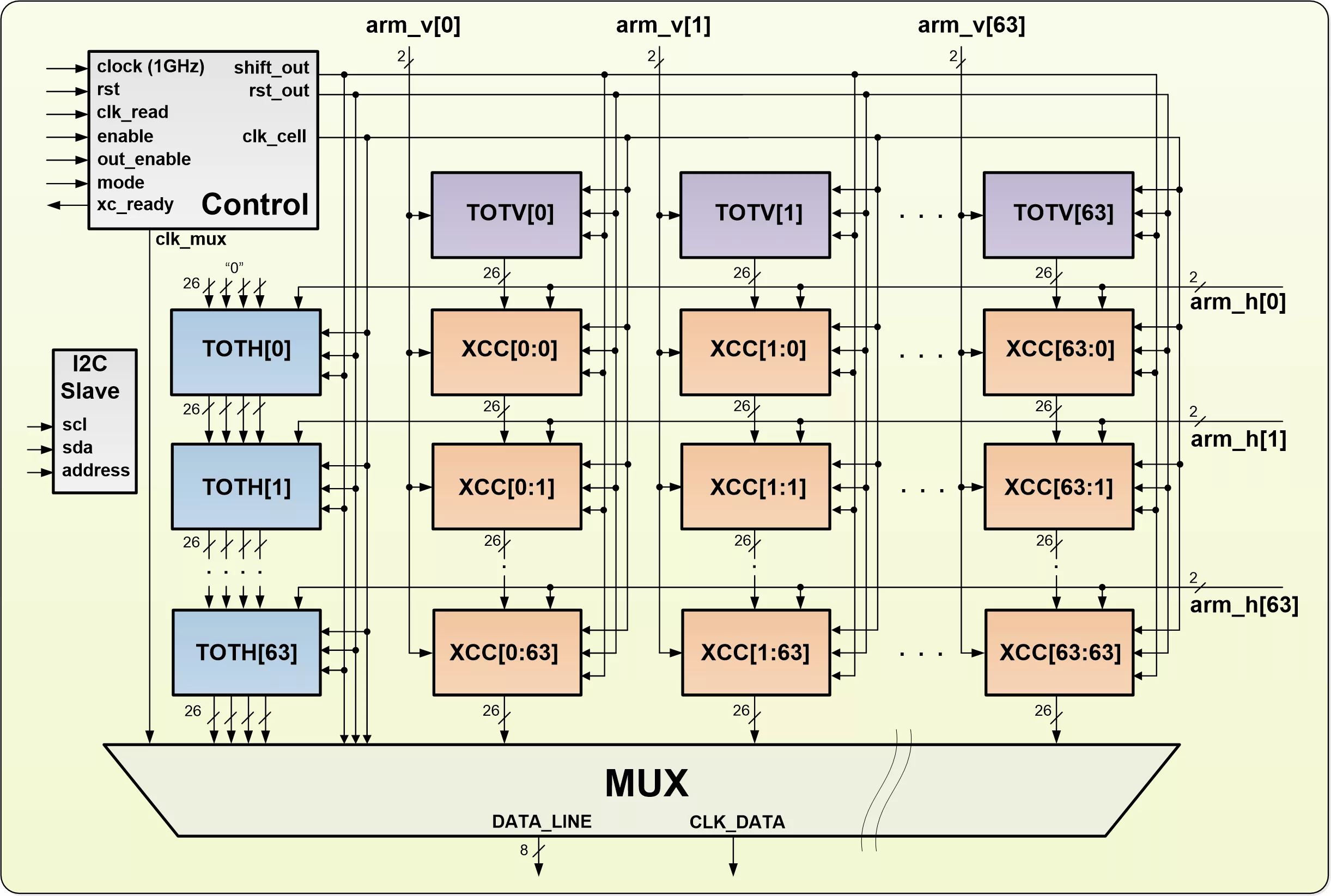
The PMCC_XCM_64x64_D IP block consists of 4096 cross-correlation cells, 64 vertical totalizers, 64 horizontal totalizers, an output multiplexer, a control circuit and the I2C slave controller with registers.
The input data {-3, -1, 1, 3} from two arms is supplied to the cross-correlation cell (XCC) which includes a multiplication unit implemented as a look-up table (LUT). There are five possible result values {0, 2, 3, 4, 6}. Therefore, each LUT has 4 binary inputs and a 3-bit correlation result. The outputs of LUTs are used as input data for counters, which count each input number. To ensure 10ms integration time, 26-bit counters are required. Power efficient ripple counters are employed for this purpose. The result of the cross-correlation is stored in the counters ready to be transmitted through common bus on demand.
The purpose of totalizers (TOTs) is to count the number of occurrences of each possible two-bit input value {-3, -1, 1, 3}. There are 64 vertical (TOTV) and 64 horizontal (TOTH) totalizers. A separate TOT is employed for each input channel. The TOT consists of a multiplication unit (LUT) and four 26-bit synchronous counters.
During the readout mode correlated data comes by the line to the multiplexer (MUX) with serialized 8 bit output. Optionally, an external clock can be applied to control the reading data rate.
Learn more about Filters Transforms IP core
Processor Architecture for High Performance Video Decode
No size fits all for signal processing on FPGA (RF Engines)
Employing general-purpose processors for radio DSP
Finally a Practical ''Do and Don't'' primer on architecting FPGA solutions for DSP design. With more do's than don’ts, the article is a down-to-basics look at how to avoid the pitfalls and realize device benefits
Regardless of whether you are using VHDL, System Verilog, or a different design capture language, there are a number of universal design techniques with which FPGA engineers should be familiar, from the very simple to the most advanced.
The real results of a double-precision matrix multiply core that can easily be extended to a full DGEMM benchmark are demonstrated.