Overview
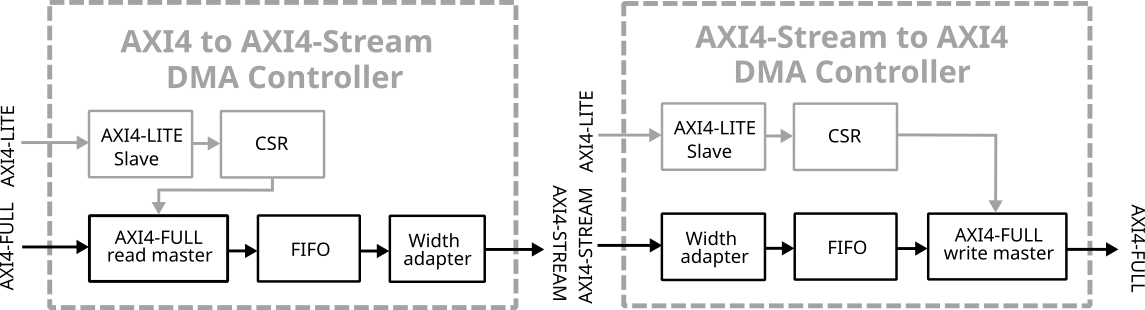
The AXI4-DMA IP core interfaces AXI4 data bus to provide data transfers from AXI4 Memory-Mapped port to AXI4-Stream port or the other way round thus serving as a Direct Memory Access controller.
The core is supplied as independent Memory-Mapped to Stream and Stream to Memory-Mapped single DMA channel modules each with its own AXI4-LITE slave. The modules operate in direct register mode, where control and status registers (CSR) are used to configure descriptors and trigger transfers from the host system. Data bus width, address width, burst length and other parameters are customizable at synthesis time, allowing flexible resource management and adjusment for diverse peripherals. Stream master and slave logic includes convenient data width converters supporting byte alligned 8, 16, 24, 32 and higher bit widths.
The EDI-AXI4-DMA core is provided as VHDL source or packaged for the Xilinx IP Integrator tool and can be combined with other Xilinx IP cores. The parameters are completely configurable in the package allowing the designer to adjust for different peripherals.
Learn more about DMA IP core
There are many IP’s today . These IP’s can be simple IP’s like Timer to complex IP’s like Accelerators. In Most of the cases IP’s are Integrated in standard way. There are cases where you have the option of Integrating it differently. This goes un-noticed or unable to be implemented due to time constraints. One such IP that would be discussed in this paper is DMA . This paper tries to explain idea of Integrating Direct Memory access(DMA) and Interrupt Control Unit(ICU) differently but final implementation requires some changes in IP. There is a possibility that alternate design explained below may be already implemented.
By Dany Nativel, Jacko Wilbrink and Tim Morin
Explore the differences between SHA-2 and SHA-3 for embedded systems, focusing on performance, design, and integration.
Modern AI SoCs are forcing architects to treat the network-on-chip as a first-order design decision. As compute density increases, the system bottleneck increasingly shifts to data movement, arbitration, and physical realization.
Is your NPU DOOMed? Quadric's Chimera GPNPU runs every AI model — and a complete DOOM engine. Find out why Quadric is different.