Overview
AI inference performance is increasingly constrained by memory bandwidth and capacity - not compute. Especially in large language models (LLMs), where the Prefill stage is compute-bound, but the Decode stage - critical for low-latency, real-time applications - is memory-bound. Traditional approaches like quantization, pruning and distillation reduce memory usage but compromise accuracy.
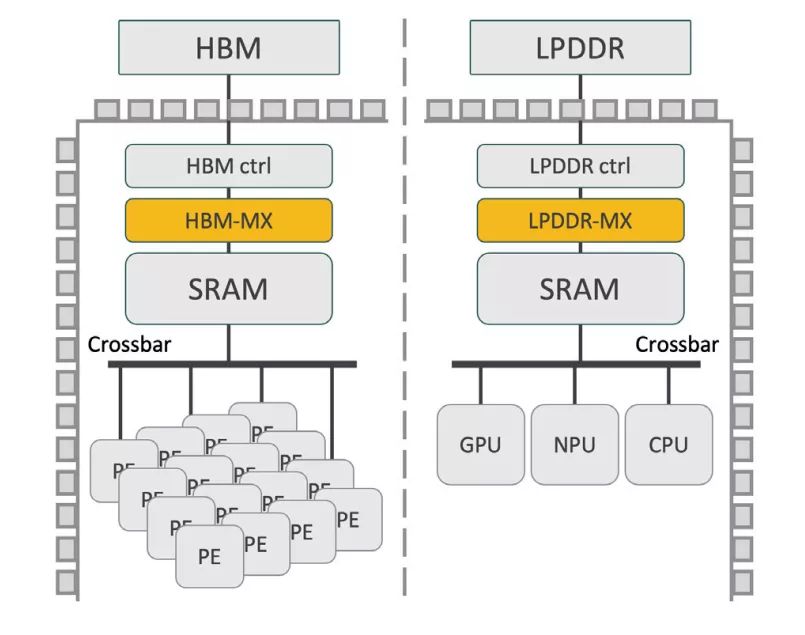
The AI-MX offers a complementary solution: lossless, nanosecond-latency memory compression, enabling up to 1.5x more effective HBM or LPDDR capacity and bandwidth. AI-MX enhances AI accelerators by transparently compressing memory traffic - without changes to DMA logic or SoC architecture.
Standards
- Compression: XZI (proprietary)
- Interface: AXI4, CHI
- Plug in compatible with industry standard memory controllers
Architecture
- Modular architecture, enables seamless scalability
- Architectural configuration parameters accessible to fine tune performance
Integration
AI-MX is available in two versions:
AI-MX G1 - Asymmetrical Architecture
- Models are compressed in software before deployment
- Hardware performs in-line decompression at runtime
- Suitable for static model data
- Up to 1.5x expansion
AI-MX G2 - Symmetrical Architecture
- Full in-line hardware compression + decompression
- Accelerates not just the model, but also KV-cache, activations, and runtime data
- Up to 2x expansion on unstructured data
- Ideal for dynamic, memory-bound workloads
Performance / KPI
| Feature |
Performance |
| Compression ratio: |
1.5x for LLM model data at BF16
1,35x - 2.0x for dynamic data i.e. KV cache and activiations |
| Throughput: |
Matches the throughput of the HBM and LPDDR memory channel |
| Frequency: |
Up to 1.75 GHz (@5nm TSMC) |
| IP area: |
(Throughput dependant - contact for information) |
| Memory technologies supported: |
HBM, GDDR, LPDDR, DDR, SRAM |
Learn more about Data Compression IP core
Data compression plays a critical role in modern computing, enabling efficient storage and faster transmission of information. Among lossless data compression algorithms, GZIP, ZSTD, LZ4, and Snappy have emerged as prominent contenders, each offering unique trade-offs in terms of compression ratio, speed, and resource utilization. This white paper evaluates these algorithms and their corresponding hardware cores, providing an in-depth comparison to help developers and system architects choose the optimal solution for their specific use case.
Part three of this three-part series explains how JPEG and MPEG compression work.
The phrase “IoT” for Internet of Things has exploded to cover a wide range of different applications and diverse devices with very different requirements. Most observers, however, would agree that low energy consumption is a key element for IoT, as many of these devices must run on batteries or harvest energy from the environment.
This paper describes an FPGA-based high-definition video processing platform. The platform supports a wide range of applications including flat-panel TV, projection TV and video monitor.
This paper presents the development of an IP core for an H.264 decoder. This state-of-the-art video compression standard contributes to reduce the huge demand for bandwidth and storage of multimedia applications. The IP is CoreConnect compliant and implements the modules with high performance constraints.
In this paper, we present a new concept and its circuit implementation for high-speed associative memories based on Hamming distance