The Ceva-NeuPro-Nano is a highly efficient and self-sufficient Edge NPU designed for Embedded ML applications.
This Edge NPU, which is the smallest of Ceva’s NeuPro NPU product family, delivers the optimal balance of ultra-low power and high performance in a small area to efficiently execute Embedded ML workloads across AIoT product categories, including Hearables, Wearables, Home Audio, Smart Home, Smart Factory, and more. Ranging from 10 GOPS up to 200 GOPS per core, Ceva-NeuPro-Nano is designed to enable always-on audio, voice, vision, and sensing use cases in battery-operated devices across a wide array of end markets. Ceva-NeuPro-Nano makes the possibilities enabled by Embedded ML into realities for low cost, energy efficient AIoT devices.
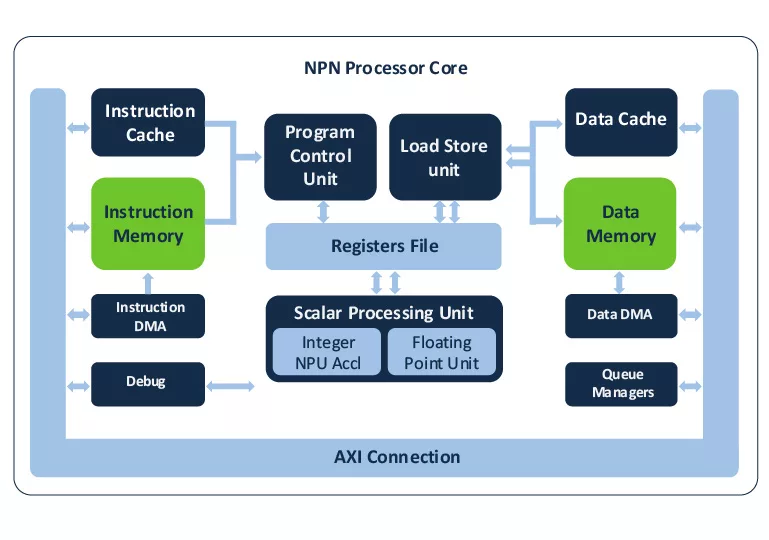
Ceva-NeuPro-Nano is a stand-alone neural processing unit (NPU), not an AI accelerator, and therefore does not require a host CPU/DSP to operate. The IP core includes all the processing elements of a standalone NPU, including code execution and memory management. The Ceva-NeuPro-Nano Embedded ML NPU architecture is fully programmable and efficiently executes neural networks, feature extraction, control code and DSP code. It also supports the most advanced machine-learning data types and operators including native transformer computation, sparsity acceleration, and fast quantization to efficiently execute a wide range of neural networks, delivering a highly optimized solution with excellent performance.
Adding to the solution’s power and efficiency, both NeuPro-Nano cores provide hardware-based decompression of weights, reducing weight memory footprint by up to 80 percent. The Ceva-NPN64 adds hardware sparsity acceleration that can double effective performance. The NeuPro-Nano is fully supported in Ceva-NeuPro Studio, which facilitates importing, compiling, and debugging models from open frameworks such as LiteRT for Microcontrollers and µTVM.