Semidynamics公布其全新一体式AI IP的张量单元效率数据
西班牙巴塞罗那– 2024年7月3日。欧洲RISC-V定制内核AI专家Semidynamics公布其运行LlaMA-2 70亿参数大语言模型 (LLM) 的‘一体式’ AI IP的张量单元效率数据。
Semidynamics的CEO Roger Espasa解释道:“传统的人工智能设计使用三个独立的计算元件:CPU、GPU(图形处理器单元)和通过总线连接的NPU(神经处理器单元)。这种传统架构需要DMA密集型编程,这种编程容易出错、速度慢、耗能大,而且必须集成三种不同的软件栈和架构。而且,NPU是固定功能的硬件,无法适应未来尚未发明的AI算法。”
“相反,Semidynamics重新发明了AI架构,并将这三个要素整合到一个单一的、可扩展的处理元件中。我们将RISC-V内核、处理矩阵乘法的张量单元(扮演NPU的角色)和处理类似激活的计算的矢量单元(扮演GPU的角色)组合到一个全集成的一体式计算元件,如图1所示。我们的新架构无DMA,使用基于ONNX和RISC-V的单个软件堆栈,在三个元件之间提供直接的零延迟连接。因此,性能更高,功耗更低,面积更好,实现更容易编程的环境,降低整体开发成本。除此之外,因为张量和矢量单元由灵活的CPU直接控制,我们可以部署任何现有或未来的AI算法,为客户的投资提供巨大保护。
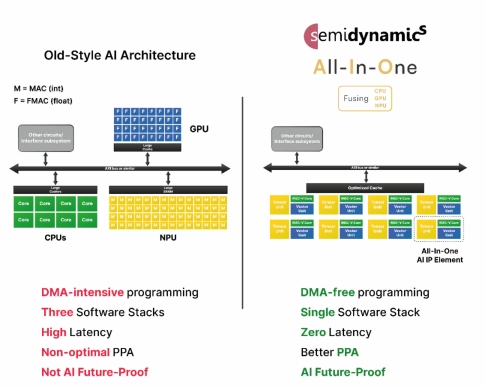
图1 传统AI架构与Semidynamics的全新一体式集成解决方案对比
大语言模型 (LLM) 已成为AI应用的关键元件。LLM在计算上由自注意层主导,如图2详细所示。这些层包括五个矩阵乘法 (MatMul)、一个矩阵Transpose和一个SoftMax激活函数,如图2所示。在Semidynamics的一体式解决方案中,张量单元 (TU) 负责矩阵乘法,而向量单元(VU)可以有效地处理Transpose和SoftMax。由于张量和矢量单元共享矢量寄存器,因此可以在很大程度上避免昂贵的内存复制。因此,在将数据从MatMul层传输到激活层以及从激活层传回时,实现零延迟和零能耗。为了保持TU和VU持续繁忙,必须有效地将权重和输入从存储器提取到矢量寄存器中。为此,Semidynamics的Gazzillion™ Misses技术提供了前所未有的数据迁移能力。通过支持大量的运行中缓存未命中,可以提前提取数据,从而提高资源利用率。而且,Semidynamics的定制张量扩展包括为获取和转换2D贴片而优化的新矢量指令,极大地改进了张量处理。
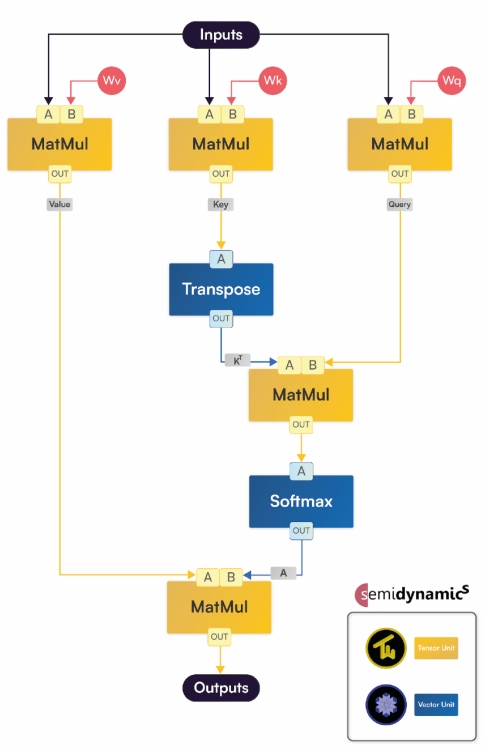
图2 LLM的自注意层
Semidynamics在其一体式元件上运行了完整的LlaMA-2 70亿参数模型(BF16权重),使用 Semidynamics的ONNX运行时执行提供程序,并计算出模型中所有MatMul层的张量单元的利用率。结果如图3所示。将结果聚在一起,并按照A张量形状演示组织。LlaMA-2共有6种不同形状,如图3中的x轴标签所示。我们从中可以看出,大多数形状的利用率都在80%以上,与其他架构形成鲜明对比。结果是在最具挑战性的条件下收集的,即一批1和首个词元计算。为了补充这些数据,图4显示了大矩阵尺寸的张量单元效率,以展示张量单元和Gazzillion™技术的综合效率。图4标注了A+B矩阵大小。我们可以从中看出,随着矩阵的N、M、P维度中的元件数量的增加,总大小(以MB为单位)迅速超过任何可能的缓存/暂存区。该图表值得注意的是,无论矩阵的总大小如何,性能都稳定在略高于70%的水平。这一令人惊讶的结果要归功于Gazzilion技术能够在主存储器和张量单元之间维持较高的流数据速率。
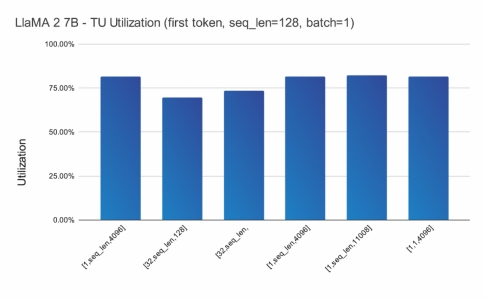
图3张量A形组织的LlaMA-2张量单元效率
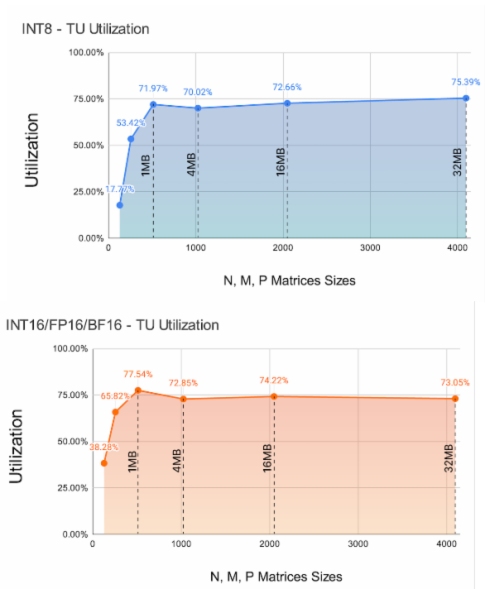
图4不同矩阵大小的8位(左侧)和16位矩阵(右侧)的张量单元利用率
Espasa总结说:“我们的全新一体式AI IP不仅具有出色的人工智能性能,而且编程也更容易,因为现在只有一个软件堆栈,而不是三个。开发人员可以使用已知的RISC-V堆栈,而且他们不必担心软件管理的本地SRAM或DMA。此外,Semidynamics提供了针对一体式AI IP优化的ONNX运行时,这使程序员能够轻松运行他们的ML模型。因此,我们的解决方案在程序员友好性和易于集成到新SOC设计方面迈出了一大步。借助一体式AI IP,我们的客户将能够以更好、更容易编程的硅的形式将所有这些好处传递给他们的客户、开发人员和用户。”
“此外,我们的一体式设计对未来AI/ML算法和工作负载的变化具有充分的弹性。对于启动一个在几年内不会上市的硅片项目的客户来说,这是一个巨大的风险保护。知道当您的硅片进入批量生产时您的AI IP仍然是相关的,这是我们技术的一个独特优势。”
Semidynamics www.semidynamics.com
2016年成立于西班牙巴塞罗那,Semidynamics®是唯一完全可定制的RISC-V处理器IP提供商,专业提供高带宽、高性能内核,其矢量单元和张量单元面向机器学习和人工智能应用。我公司为私人公司,是RISC-V联盟的战略成员。
Related Semiconductor IP
- RISC-V IOPMP IP
- RISC-V Debug & Trace IP
- Gen#2 of 64-bit RISC-V core with out-of-order pipeline based complex
- 64-bit RISC-V core with in-order single issue pipeline. Tiny Linux-capable processor for IoT applications.
- Tiny, Ultra-Low-Power Embedded RISC-V Processor
Related News
- Semidynamics 推出首款完全相干 RISC-V 张量单元,助力人工智能应用
- Semidynamics宣布推出RISC-V市场上最大的、完全可定制的矢量单元
- MIPI D-PHY v3.0 将物理层接口的数据速率提升一倍,并同时扩展电源效率
- Semidynamics发布完全可定制的四路Atrevido 423 RISC-V内核,用于大数据应用